Network Redundancy: ออกแบบเครือข่ายให้มี Failover ไม่ล่ม ปี 2026
สวัสดีครับน้องๆ ชาว Siam Lancaard ทุกท่าน! พี่เชื่อว่าหลายคนคงเคยเจอปัญหาเครือข่ายล่มกลางอากาศกันมาบ้าง ไม่ว่าจะตอนกำลังประชุมสำคัญ, ตอนกำลังโอนเงิน, หรือแม้แต่ตอนกำลังดูซีรีส์เรื่องโปรดอยู่ดีๆ ภาพก็ค้าง… เหตุการณ์เหล่านี้มันน่าหงุดหงิดสุดๆ ใช่ไหมล่ะครับ?
ในโลกยุคดิจิทัลปี 2026 ที่ทุกอย่างเชื่อมต่อกันหมด เครือข่ายที่เสถียรและพร้อมใช้งานตลอดเวลาจึงมีความสำคัญอย่างยิ่งยวด ลองคิดภาพตามว่าถ้าเครือข่ายธนาคารล่ม, ระบบโรงพยาบาลล่ม, หรือแม้แต่ระบบควบคุมการจราจรล่ม จะเกิดอะไรขึ้น? ความเสียหายคงประเมินค่าไม่ได้เลยทีเดียว
ดังนั้น วันนี้พี่เลยจะมาแชร์ประสบการณ์และเทคนิคในการออกแบบเครือข่ายให้มี Network Redundancy หรือระบบสำรอง เพื่อให้มั่นใจว่าเครือข่ายของเราจะไม่ล่มง่ายๆ และมี Failover ที่ราบรื่นเมื่อเกิดเหตุการณ์ไม่คาดฝันขึ้น มาดูกันเลยครับ!
ทำความเข้าใจ Redundancy และ Failover
ก่อนอื่น เรามาทำความเข้าใจความหมายของคำว่า Redundancy และ Failover กันก่อน Redundancy ในบริบทของเครือข่าย หมายถึง การมีองค์ประกอบต่างๆ ซ้ำซ้อนกัน เช่น มีอุปกรณ์เครือข่ายหลายตัว, มีเส้นทางเชื่อมต่อหลายเส้นทาง, หรือมีระบบไฟฟ้าสำรอง เพื่อให้เมื่อองค์ประกอบใดองค์ประกอบหนึ่งเกิดปัญหา อีกองค์ประกอบหนึ่งสามารถเข้ามาทำงานแทนได้ทันที
ส่วน Failover คือกระบวนการที่ระบบจะสลับไปใช้องค์ประกอบสำรองโดยอัตโนมัติเมื่อองค์ประกอบหลักล้มเหลว กระบวนการนี้ควรจะเกิดขึ้นอย่างรวดเร็วและราบรื่นที่สุด เพื่อลดผลกระทบต่อผู้ใช้งาน
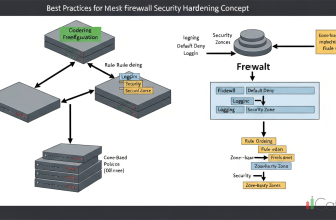
Redundancy ที่ Layer ต่างๆ ใน Network
การทำ Redundancy สามารถทำได้ในหลาย Layer ของเครือข่าย ตั้งแต่ Layer 1 (Physical Layer) ไปจนถึง Layer 7 (Application Layer) แต่ที่สำคัญที่สุดคือ Layer 2 (Data Link Layer) และ Layer 3 (Network Layer) เพราะเป็น Layer ที่เกี่ยวข้องกับการส่งข้อมูลโดยตรง
- Physical Layer: ใช้การเชื่อมต่อแบบ Multi-Homing คือมีสาย LAN หลายเส้นเชื่อมต่อจาก Server ไปยัง Switch หลายตัว
- Data Link Layer: ใช้เทคโนโลยี Link Aggregation (LAG) หรือ EtherChannel เพื่อรวมหลายๆ Links เป็น Link เดียวที่มี Bandwidth สูงขึ้น และมี Redundancy ในตัว
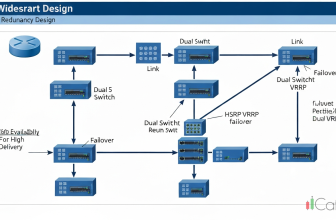
- Network Layer: ใช้ Protocol อย่าง HSRP, VRRP, หรือ GLBP เพื่อสร้าง Virtual Router ที่มี Router หลายตัวทำงานร่วมกัน หาก Router ตัวใดตัวหนึ่งล้มเหลว Router ตัวอื่นจะเข้ามาทำหน้าที่แทนโดยอัตโนมัติ
เจาะลึก HSRP, VRRP, และ GLBP
HSRP (Hot Standby Router Protocol), VRRP (Virtual Router Redundancy Protocol), และ GLBP (Gateway Load Balancing Protocol) เป็น Protocol ที่ใช้ในการทำ Redundancy ใน Network Layer แต่ละ Protocol มีข้อดีข้อเสียแตกต่างกันไป
HSRP เป็น Protocol ที่พัฒนาโดย Cisco VRRP เป็น Standard Protocol ที่สามารถใช้ได้กับอุปกรณ์จากหลาย Vendor ส่วน GLBP เป็น Protocol ที่พัฒนาโดย Cisco เช่นกัน แต่มีความสามารถในการ Load Balancing เพิ่มเติม
ตารางเปรียบเทียบ HSRP, VRRP, และ GLBP:
| คุณสมบัติ | HSRP | VRRP | GLBP |
|---|---|---|---|
| Vendor | Cisco | Standard | Cisco |
| Load Balancing | No | No | Yes |
| Complexity | Simple | Simple | Complex |
| Scalability | Limited | Limited | Good |
การเลือกใช้ Protocol ใดขึ้นอยู่กับความต้องการและความซับซ้อนของเครือข่ายของเรา ถ้าต้องการความง่ายและมีอุปกรณ์ Cisco เป็นหลัก HSRP ก็เป็นตัวเลือกที่ดี แต่ถ้าต้องการความยืดหยุ่นและใช้งานอุปกรณ์จากหลาย Vendor VRRP อาจจะเหมาะสมกว่า และถ้าต้องการ Load Balancing ด้วย GLBP ก็เป็นทางเลือกที่น่าสนใจ
Case Study: Redundancy ใน Data Center
ลองมาดูตัวอย่างจริงในการออกแบบ Redundancy ใน Data Center กันบ้างครับ Data Center เป็นสถานที่ที่ต้องการความพร้อมใช้งานสูงที่สุด ดังนั้น Redundancy จึงเป็นสิ่งจำเป็น
Scenario: Data Center แห่งหนึ่งมี Server จำนวนมากที่ให้บริการ Application ที่สำคัญต่อธุรกิจ บริษัทต้องการออกแบบเครือข่ายให้มีความพร้อมใช้งาน 99.999% (Five Nines) หรือ Downtime ไม่เกิน 5 นาทีต่อปี
Solution:
- Physical Layer: ใช้ Multi-Homing โดยให้ Server แต่ละตัวมี NIC (Network Interface Card) อย่างน้อย 2 ตัว เชื่อมต่อกับ Switch คนละตัว
- Data Link Layer: ใช้ Link Aggregation (LAG) เพื่อรวม Links ระหว่าง Server และ Switch ให้มี Bandwidth สูงขึ้น และมี Redundancy ในตัว
- Network Layer: ใช้ VRRP เพื่อสร้าง Virtual Router ที่มี Router 2 ตัวทำงานร่วมกัน หาก Router ตัวใดตัวหนึ่งล้มเหลว Router อีกตัวจะเข้ามาทำหน้าที่แทน
- Power: ติดตั้ง UPS (Uninterruptible Power Supply) และ Generator เพื่อสำรองไฟในกรณีที่ไฟดับ
- Cooling: ติดตั้งระบบ Cooling ที่มี Redundancy เพื่อป้องกัน Server ร้อนเกินไป
ด้วย Solution นี้ Data Center จะมีความพร้อมใช้งานสูงมาก และสามารถรับมือกับเหตุการณ์ไม่คาดฝันต่างๆ ได้อย่างมีประสิทธิภาพ
Tips & ข้อควรระวังในการทำ Network Redundancy
การทำ Network Redundancy ไม่ใช่แค่การติดตั้งอุปกรณ์สำรองเท่านั้น แต่ยังต้องมีการวางแผนและทดสอบอย่างรอบคอบ เพื่อให้มั่นใจว่าระบบ Failover จะทำงานได้อย่างถูกต้องและรวดเร็ว
- วางแผนอย่างรอบคอบ: กำหนดเป้าหมายความพร้อมใช้งาน (Availability) ที่ต้องการ, วิเคราะห์ความเสี่ยง, และออกแบบระบบให้เหมาะสมกับงบประมาณ
- ทดสอบระบบอย่างสม่ำเสมอ: จำลองสถานการณ์ต่างๆ เช่น อุปกรณ์ล้มเหลว, สาย LAN ขาด, หรือไฟดับ เพื่อทดสอบว่าระบบ Failover ทำงานได้ตามที่คาดหวัง
- Monitor ระบบอย่างใกล้ชิด: ติดตั้งระบบ Monitoring เพื่อตรวจสอบสถานะของอุปกรณ์เครือข่าย และแจ้งเตือนเมื่อเกิดปัญหา
- Update Firmware และ Software อย่างสม่ำเสมอ: เพื่อแก้ไข Bug และช่องโหว่ด้านความปลอดภัย
- Document ระบบอย่างละเอียด: เพื่อให้ง่ายต่อการบำรุงรักษาและแก้ไขปัญหา
ที่สำคัญ อย่าลืมว่า Redundancy ไม่ใช่ยาวิเศษที่แก้ได้ทุกปัญหา การทำ Redundancy ที่มากเกินไปอาจทำให้ระบบซับซ้อนและยากต่อการบำรุงรักษา ดังนั้น ควรเลือกทำ Redundancy ในส่วนที่สำคัญที่สุด และเหมาะสมกับความต้องการของเรา
ตัวเลข 2026 กับ Redundancy
ในโลกปี 2026 ที่เทคโนโลยีเปลี่ยนแปลงอย่างรวดเร็ว ความสำคัญของ Network Redundancy จะยิ่งมากขึ้นเรื่อยๆ IoT (Internet of Things) จะแพร่หลายมากขึ้น, Cloud Computing จะเป็นเรื่องปกติ, และ Application ต่างๆ จะมีความซับซ้อนมากขึ้น ทำให้เครือข่ายต้องรองรับปริมาณข้อมูลและการใช้งานที่เพิ่มขึ้นอย่างมหาศาล
ดังนั้น การออกแบบเครือข่ายให้มีความยืดหยุ่น, ปรับตัวได้ง่าย, และมี Redundancy ที่ดีจึงเป็นสิ่งจำเป็น เพื่อให้ธุรกิจสามารถดำเนินต่อไปได้อย่างราบรื่น แม้ในสถานการณ์ที่ท้าทาย
ทิ้งท้าย: ลงทุนกับ Redundancy เพื่ออนาคต
การลงทุนใน Network Redundancy อาจดูเหมือนเป็นการลงทุนที่สิ้นเปลืองในระยะสั้น แต่ในระยะยาว มันคือการลงทุนที่คุ้มค่า เพราะมันช่วยลดความเสี่ยงจาก Downtime, เพิ่มความน่าเชื่อถือของระบบ, และสร้างความได้เปรียบในการแข่งขัน
พี่หวังว่าบทความนี้จะเป็นประโยชน์กับน้องๆ ทุกคนนะครับ อย่ารอให้เครือข่ายล่มก่อนแล้วค่อยคิดถึง Redundancy ลงมือวางแผนและออกแบบเครือข่ายให้มี Failover ตั้งแต่วันนี้ เพื่ออนาคตที่สดใสขององค์กรเรา!